

2026 resolution check-in: i wanted to be way more deliberate about what i consume, remember, and revisit. this project is my attempt to stop “highlight hoarding” and start building an actual memory system.
I love learning. Like genuinely, obsessively love it. Technology, psychology, philosophy, behavioral finance, neuroscience, entrepreneurship.. I will read about basically anything that seems interesting enough. And there is always something that seems interesting enough.
So I consume a lot. Books, podcasts, YouTube, arXiv papers, random blog posts at 1am. A lot.
And for the longest time I told myself this was fine. That it was all going in somewhere. That it was compounding.
It was not.
I had to sit with that for a bit before I could admit it honestly. I was not learning. I was collecting. There is a difference and I kept blurring it.
The thing is, the science on this is pretty unambiguous. Active recall is how humans actually encode memory, not reading, not highlighting, not listening. The effortful retrieval is what wires it in. Again, this is my learnings from few leaders like Dr. Andrew Huberman. There are also few leading learning platforms like MathAcademy that are built the way they are. The friction is the feature.
I had built the opposite of that. A giant passive collection with no retrieval loops whatsoever. Thousands of highlights across Kindle and Snipd and papers I told myself I would come back to. I felt productive because the pile kept growing. The pile growing is not the same as learning.
And then separately, but related: I could not answer basic questions like “where did I read that thing about attention and memory?” I knew I had read it somewhere. But somewhere is not a useful address.
Motivation to build this system
Here is the thing I keep thinking about.
LLMs are genuinely incredible at execution. Give them a clear enough task and they will outperform most people on it. But as Chris Lattner argues in his essay on the future of software, that changes what matters in software engineering. If implementation keeps getting cheaper, the scarce skill shifts upward: choosing the right problems, forming better abstractions, and exercising real judgment.
And that is part of why I keep coming back to this project. If execution keeps getting cheaper, then the advantage shifts toward people with better judgment, better abstractions, and better recall of what matters. In that world, a memory system is not just convenient, but can lead to a greater advantage.
So this project went from something I wanted to build someday to something that started to feel needed more than ever.
What is actually running now
This is not the first time I have tried to build this. A year and a half ago I built a Chrome extension and a small mobile app to capture and convert articles into audio. The core instinct was the same: stop losing things. It hit a ceiling pretty fast, Kindle was not supported, Zotero was not supported, every new source was its own project. It went quiet. But the idea did not go away. This is the version where I think I got the architecture right. Demo of the v1 that we (My friend and I) presented at a hackathon
I use Readwise as the ingestion hub. It already had months of my highlights from Kindle and Snipd sitting there, and it has an export API I could build on top of. I did not need to rebuild ingestion from scratch. What Readwise could not give me was a recall layer I actually trusted. The review system treated every highlight the same. The chat interface had no concept of time, I could not ask “what have I been reading about this week” and get a useful answer. So I kept Readwise for intake and built everything downstream myself.
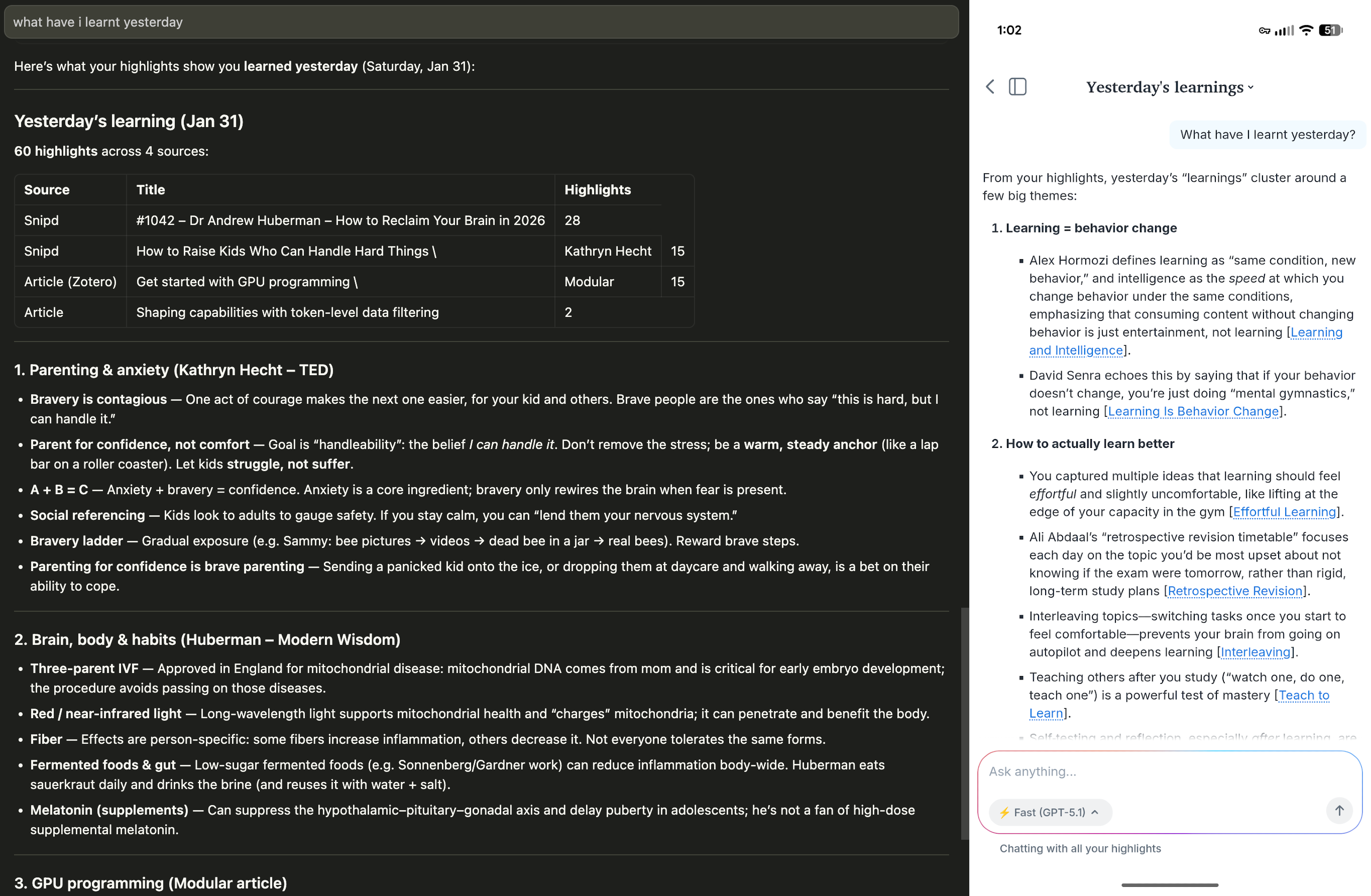
Comparision of query capabilities of my own system(left) vs readwise(right).
This is a comparison of query capabilities in temporal context of my own system(left) vs readwise(right).
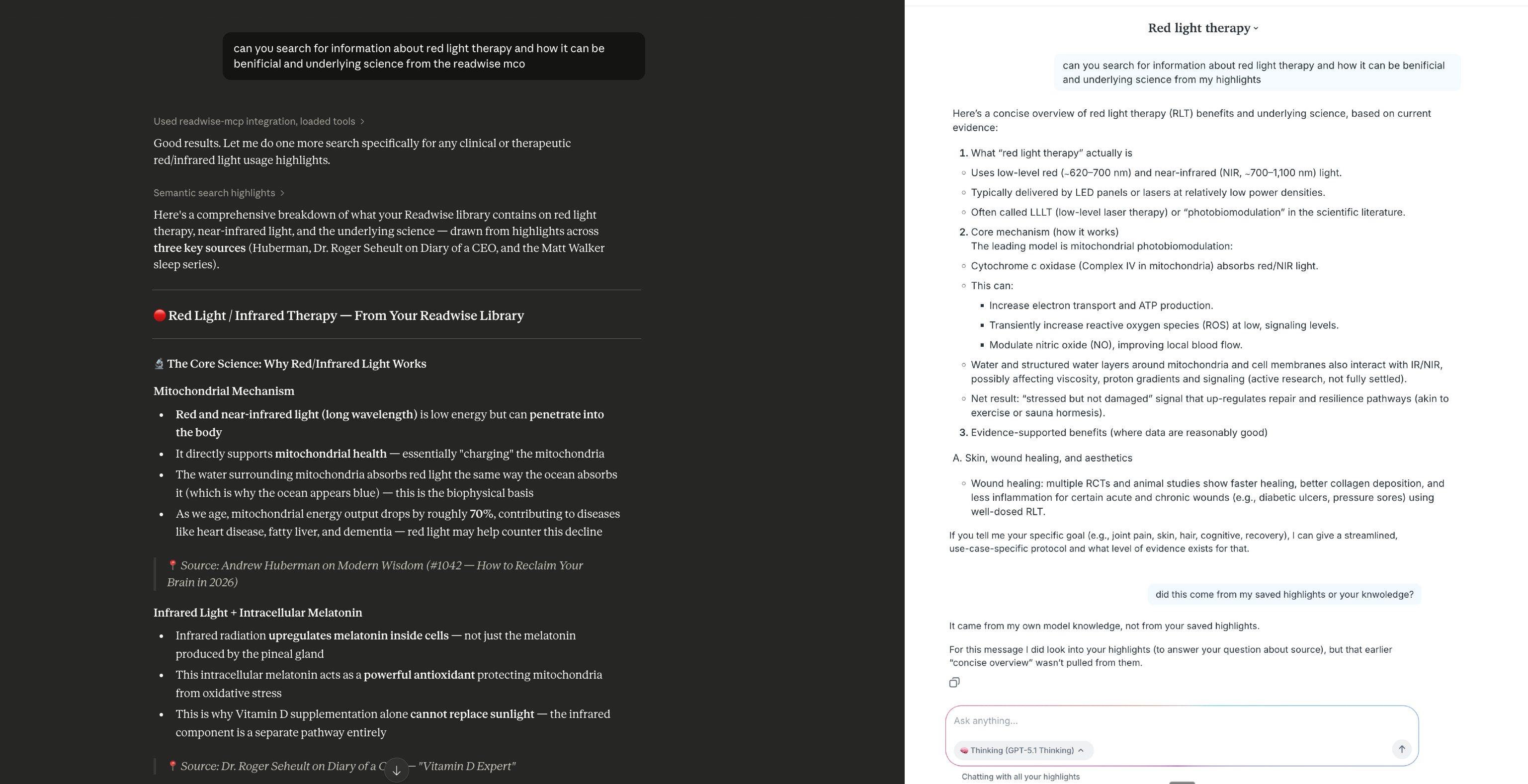
This is a comparison where it fails to access highlights about specific topic
The basic flow:
Capture —> Readwise —> Supabase Postgres —> my query layer —> me
Highlights come in from Kindle, Snipd, Zotero, and YouTube. Readwise normalizes them. An incremental sync runs every few hours and pulls only new or updated data into my own Postgres instance on Supabase. Embeddings get generated in the background using Gemini’s embedding API and stored with pgvector.
YouTube was my biggest capture gap. I closed it by building two tools: a Chrome extension for in-player timestamp capture, and a Raycast extension for fast keyboard-driven capture from whatever tab is active, including youtube. Before anything goes to Readwise I can review what should actually go there. An optional processing step adds transcript context and runs a light LLM pass, so instead of random timestamps floating around I get structured notes that fit the rest of the system, similar to how snipd does it for podcasts.
This is the main view of the frontend
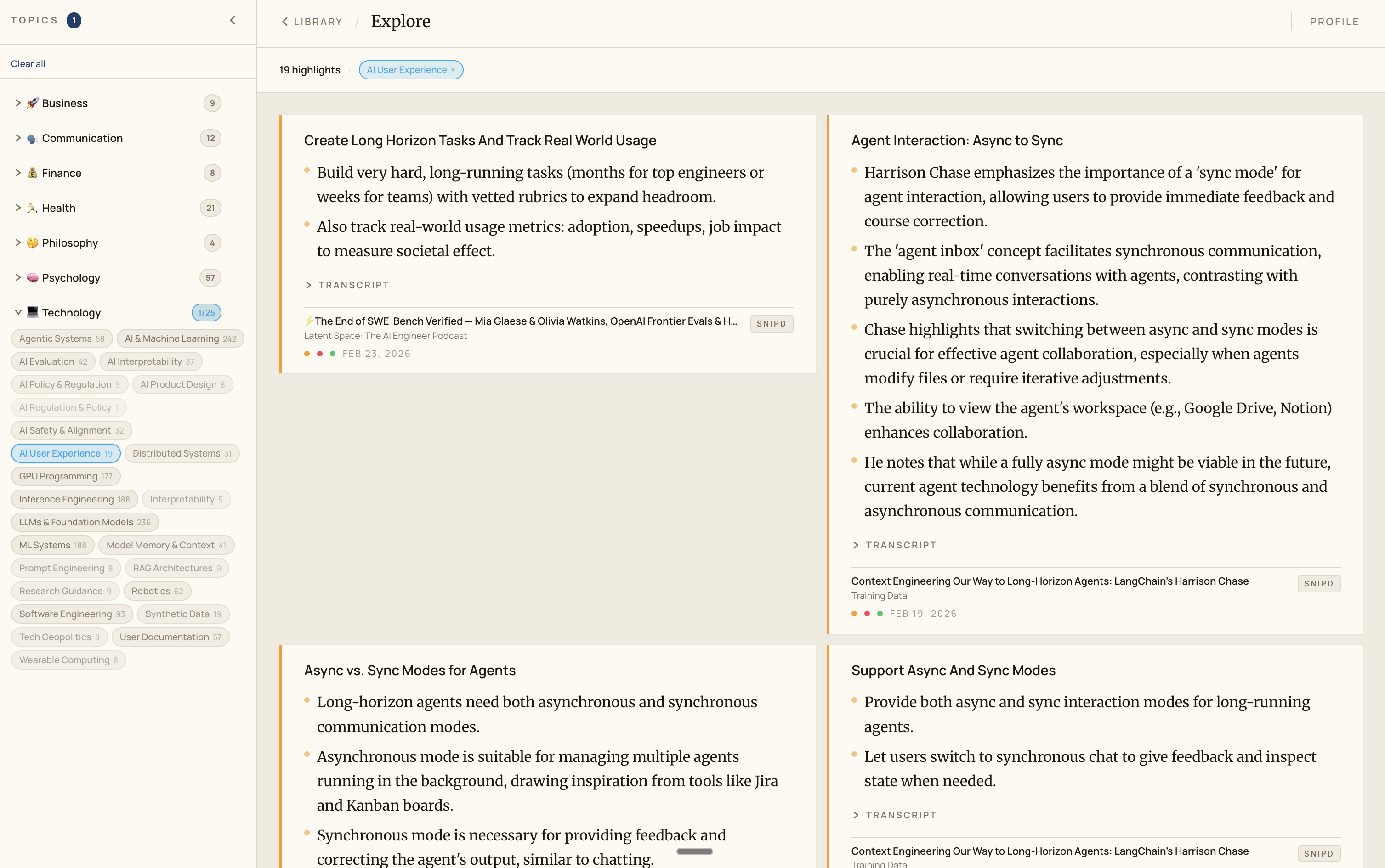
This is the tag explore view of the frontend
The query layer
I started by querying straight through the raw Supabase MCP. That kind of works but it is brittle. The model regenerates SQL every single time, output varies, and you cannot build reliable patterns on top of it.
Now I have a custom FastMCP server with tools built around the queries I actually reach for. Now I have a custom FastMCP server with tools built around the queries I actually reach for:
search_highlightsget_latest_highlightssemantic_search_highlightsget_highlights_by_book
There is an execute_sql escape hatch for ad-hoc queries too, but it runs in a read-only transaction so mutations fail fast.These tools encode the patterns I have learned from actually using the system. They get better as I understand my own usage better.
The part I think about the most: agents and memory
This is where it gets a little more personal and a little less polished.
I have always been a huge Jarvis fan. Like embarrassingly so. The idea of an assistant that actually knows what you care about, not from you telling it in a system prompt, but from observing your patterns over time, your recurring queries, the themes that keep coming back, and then becoming genuinely useful in a proactive way.. that has been a dream project idea for me for years.
Most agents stay generic because they have no real personal context. They know what you tell them in the moment. That is not Jarvis. That is a very fast search box.
And knowledge is only one slice of a life. What I really want is for this to eventually connect to other parts of mine too. Health data through the Whoop API. Finance maybe helping me manage my portfolio and track my investments. The stuff that actually shapes how I live day to day. Because the interesting version of this is not “here are your highlights from last week.” It is something more like: you mention that you have been feeling drained lately, and the agent already knows your sleep has been slipping, your calendar has been packed, and your workouts have been heavier than usual. Instead of giving generic advice, it comes back with a realistic plan that fits your schedule and helps you recover over time. Personalized not because you filled out a profile but because it has been paying attention.
That is the version I want to build toward. And this is where it stops being a knowledge tool and starts being something closer to what I actually had in mind.
What is next
Three things I am actively thinking about:
- Flashcard toggle for high-signal highlights. Not everything should become a card. But technical highlights, concept-heavy ones, things that genuinely surprised me.. those should be one-click promotable to a spaced repetition queue. This is the active recall piece I am still missing.
- Cross-source synthesis. If the same idea shows up in a book and a podcast and a paper, I want the system to notice that and propose a synthesized note I can edit and store back. This is the connection layer. This is the thing I wanted since the beginning.
- Better auto-tagging. Broad and specific tags together so I can navigate both top-down by domain and deep by niche. Eventually this becomes an evolving map of what I actually care about and how my interests shift over time.
Look, this is overbuilt for a personal project. I know that.
But the things I am trying to get right here.. safe tool interfaces over raw model output, practical RAG that is not just vector similarity, retrieval quality that improves with usage, constrained agent behavior.. these are also the things I care about in production AI systems at work. So this is also just my best sandbox for thinking through them without stakes.
It is not done. There is a lot more I want to build. But it is real and it is running and it is useful to me today.
For those interested in the architecture, here is the current architecture diagram:
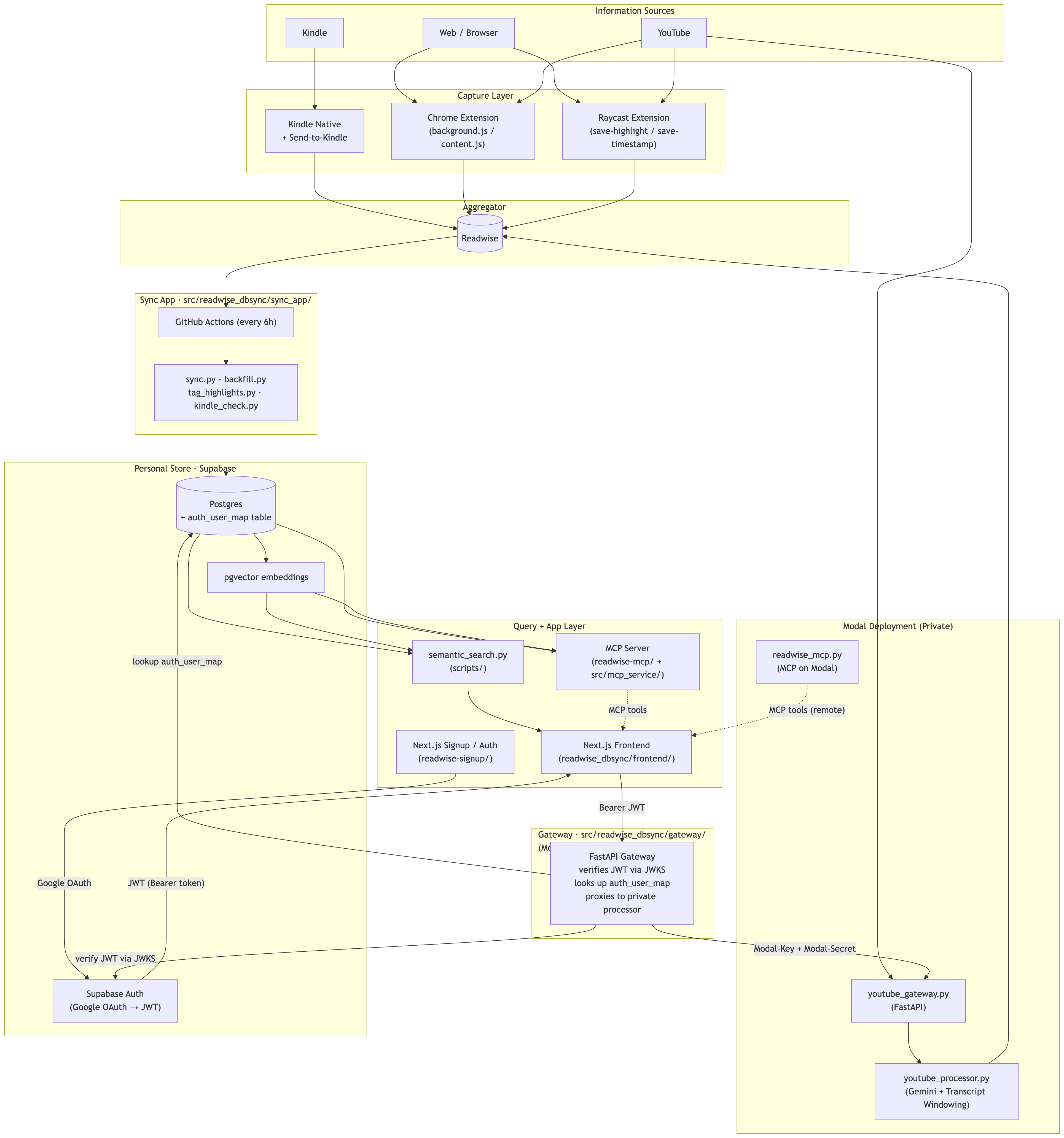
And for tech stack, here is the current tech stack:
| Component | Technology |
|---|---|
| Aggregation Hub | Readwise |
| Database | Supabase Postgres |
| Vector Layer | pgvector (vector(1536)) |
| Sync + Ingestion | Python + GitHub Actions |
| Embeddings | Gemini embedding API (gemini-embedding-001, 1536-dim) |
| LLM / Enrichment | Google GenAI SDK + Gemini |
| YouTube Enrichment API | FastAPI + Gemini transcript windowing |
| Processor Hosting | Modal (private processor + public gateway) |
| Auth | Supabase Auth (Google OAuth → JWT) + FastAPI Gateway |
| Query Interface | FastMCP |
| Frontend | Next.js 16 + React 19 (App Router) — main app + signup/auth app |
| Capture Extensions | Chrome extension + Raycast extension |
If you are building something in this space I would genuinely love to talk about it.